IOPS, VDI, IOMETER — Часть 1
Идея этой статьи в том, что пока я не нашел адекватной инструкции по пользованию такой классической программой как IOmeter. Также, не нашел готовых профилей для нагрузки, в зависимости от типа задач, это тоже отдельный вопрос. Постараюсь рассказать максимально просто про IOPS, с картинками и с неким углублением в VDI (виртуализицию рабочих столов) на ОС Windows 10.
Сама инструкция будет во второй статье, сначала начнем с теории, будет много текста.

Windows, изначально, был спроектирован для использования локальных дисков и требует постоянный доступ к дисковой подсистеме, даже в момент простоя. В дополнение к этому, Windows будет использовать столько операций ввода-вывода или пропускной способности диска, насколько это возможно. Это означает, что ВМ (виртуальная машина) при использовании общего хранилища, пытается перетянуть одеяло доступных IOPS на себя. В результате, когда вы виртуализируете много рабочих станций, и у вас общее хранилище данных (SAN или NAS), все они конкурируют за использование максимально возможного дискового ввода-вывода, чтобы максимизировать свою производительность (без знания потребностей других ВМ которые используют тот же аппаратный ресурс). Если ОС не будет получать достаточно требуемого кол-ва операций ввода-вывода, производительность рабочего стола снизится, и пользователи увидят его в виде длительного времени загрузки / входа в систему, медленного запуска приложений и в целом, низкой производительности рабочего стола.
Основная нагрузка на диск идет в момент загрузки ОС, во время проверки антивирусом, установки обновлений и их очистки. В связи с этим, существует одна из главных проблем под названием «boot storm», когда люди приходят на свои рабочие места, скажем, в 9 утра, и включают компьютер. Еще Windows, при наличии в нем антивируса, более чем в 2 раза увеличивает кол-во потребляемой памяти, благо, с этим в последнее время все проще, сервера стали нести на себе большой объем RAM. Однако, главная проблема в антивирусе, это критическое увеличение потребляемых IOPS. Это, конечно, проблема VDI инфраструктуры, но об этом позже, смысл не меняется.
Windows складывает операции чтения и записи в очереди, чтобы обработать их когда ресурс станет доступным. Очереди чтения/записи ведут к задержкам (latency), задержки же превращаются в проблемы с производительностью. Все становится еще хуже, когда мы имеем дело с виртуализованной ОС, т.к. это в свою очередь накладывает свои «накладные расходы» связанные с сетью передачи данных, гипервизором и др. Таким образом, отклик диска из 5мс на локальных дисках, превращается в 20+ мс при тех же нагрузках на виртуализации при конкуретном (когда каждая виртуальная машина пытается урвать себе как можно больше дисковых операций) использовании ресурсов другими ВМ на этой же системе хранения.
Окей, вернемся к IOPS. Как же их измерять? Измерение IOPS может вызвать затруднения, поскольку оно не связано напрямую с производительностью. Эта комбинация IOPS которые ОС запросила (requested), и тех, которые ей доступны (available), это дает нам задержку дисковой подсистемы (storage latency). Вот эта storage latency уже напрямую связана с производительностью, т.к. большая задержка приводит к тому, что ОС и приложения перестают отвечать на запросы (классические «фризы» и подвисания системы»). Хотелось бы как-то измерить IOPS, которую запрашивает Windows. Сделать это можно через vscsiStats (как с этим работать, можно почитать в отдельной статье). Есть возможность измерить IOPS доступные. Чем ближе значение очереди к нулю, тем ближе к идеальным значения запрошенных и доступных IOPS. Это одна из основных наших задач — снижение дисковой очереди.
Что нам понадобится — Perfmon (Perfomance Monitor) и его Счетчики (counters), ESXTOP (команда статистики ESXI) и IOmeter.
Счетчики, которые нам пригодятся: Раздел PhysicalDisk
1. Disk Reads/sec — IOPS на чтение.
2. Disk Writes/sec — IOPS на запись.
3. Disk Transfers/sec — Общее кол-во IOPS.
4. Current Disk Queue Length — Глубина очереди, которая скопилась в ОС.


Значения в поле Value следует читать до запятой, т.е. ниже, на скриншот, это 475 IOPS.

На картинке ниже, у нас все плохо, очередь скопилась, что вызвало увеличение времени отклика (response time, оно же latency).

Следующее, что нам потребуется — ESXTOP
Заходим на ESXI, запускаем esxtop, жмем U (нас перекинет в раздел по части дисков).
 Глянем поближе
Глянем поближе
Нас интересуют вот эти показатели (можно обновлять результаты по нажатию кнопки 2):

Из того, что нам нужно в этих блоках:
1. CMDS/s — это сумма IOPS в READS/s и WRITES/s
2. GAVG/cmd — это задержка
Как же, в итоге, тестировать нашу инфраструктуру? Продолжим это во второй статье.
Измерение производительности и IOPS жестких дисков и СХД в Windows
Одной из основных метрик, позволяющих оценить производительность существующей или проектируемой системы хранения данных является IOPS (Input/Output Operations Per Second — количество операций ввода/вывода). Говоря простым языком, IOPS – этой количество блоков, которое успевает считаться или записаться на носитель или файловую систему в единицу времени. Чем это число больше – тем больше производительность данной дисковой подсистемы (откровенно говоря, само по себе значение IOPS стоит рассматривать в комплексе с другими характеристиками СХД, таким как средняя задержка, пропускная способность и т.п.).
В этой статье мы рассмотрим несколько способов измерения производительности используемой системы хранения данных в IOPS под Windows (локальный жесткий, SSD диск, сетевая папка SMB, CSV том или LUN на СХД в сети SAN).
Счетчики производительности дисковой подсистемы Windows
Вы можете оценить текущий уровень нагрузки на дисковую подсистему с помощью встроенных счетчиков производительности Windows из Performance Monitor. Чтобы собрать данные по этим счетчикам:
Как интерпретировать результаты производительности дисков в Perfmon? Для быстрого анализа производительности дисковой подсистемы необходимо посмотреть на значения как минимум следующих 5 счетчиков.
Тестирование IOPS в Windows с помощью DiskSpd
Для генерации нагрузки на дисковую подсистему и измерения ее производительности Microsoft рекомендует использовать утилиту DiskSpd (https://aka.ms/diskspd). Эта консольная утилита, которая в несколько потоков может осуществлять операции I/O с указанным таргетом. Я довольно часто использую эту утилиту чтобы замерить производительность СХД в IOPS и получить максимальную скорость чтения/записи c данного сервера (можно конечно измерить производительность и со стороны СХД, в этом случае diskspd будет использоваться для генерации нагрузки).
Утилита не требует установки, просто скачайте и распакуйте архив на локальный диск. Для x64 битных систем используйте версию diskspd.exe из каталога amd64fre.
Я использую такую команду для тестирования диска:
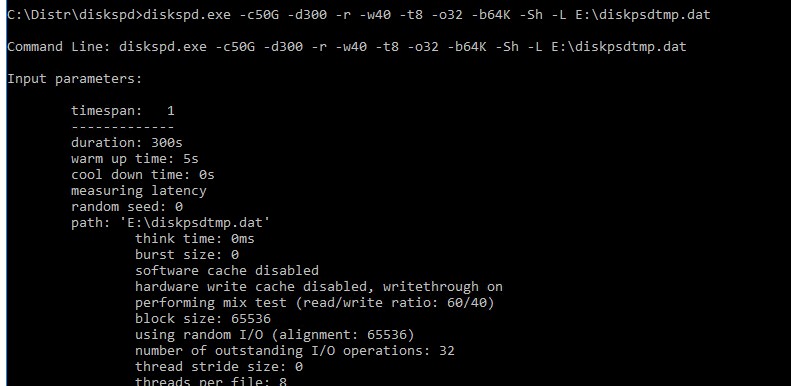
После окончания стресс-теста из полученных таблиц можно получить средние значения производительности.
Например, в моем тесте получены следующие общие данные про производительности (Total IO):
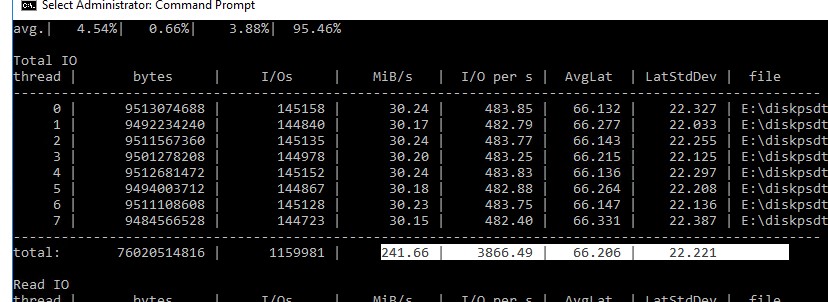
Можно получить отдельные значения только по операциям чтения (секция Read IO ) или записи (секция Write IO ).
Протестировав с помощью diskspd несколько дисков или LUN на СХД, вы сможете сравнить их или выбрать массив с нужной производительностью под свои задачи.
Как получить IOPS и производительность дисковой подсистемы с помощью PowerShell?
Недавно мне на глаза попался PowerShell скрипт (автор Microsoft MVP, Mikael Nystrom), являющийся по сути надстройкой над утилитой SQLIO.exe (набора тестов для расчета производительности файлового хранилища).
Итак, скачайте архив содержащий 2 файла: SQLIO.exe и DiskPerformance.ps1 (disk-perf-iops.ZIP — 73Кб) и распакуйте архив в произвольный каталог.
Пример запуска PowerShell скрипта для определения IOPS:
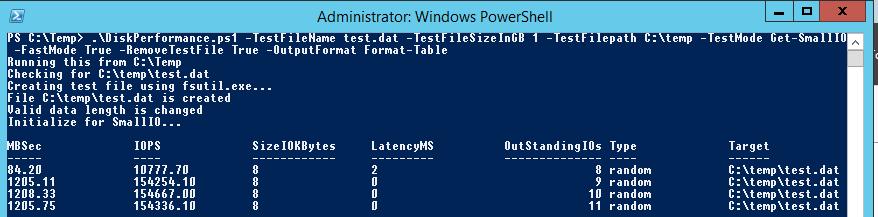
Я использовал в скрипте следующие аргументы:
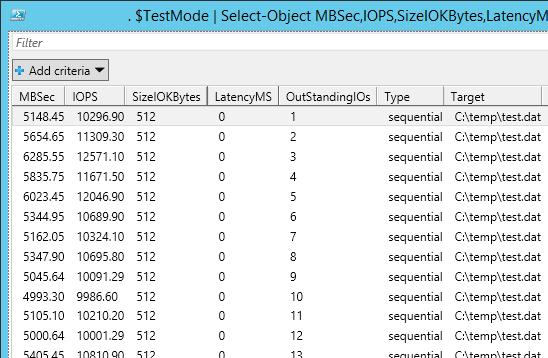
В нашем случае дисковый массив (тестировался виртуальный vmdk диск на VMFS хранилище, расположенном на дисковой полке HP MSA 2040 с доступом через SAN) показал среднее значение IOPS около 15000 и скорости передачи данных (пропускная способность) около 5 Гбит/сек.
В следующей таблице указаны примерные значения IOPS для различных типов дисков:
| Тип | IOPS |
| SSD(SLC) | 6000 |
| SSD(MLC) | 1000 |
| 15K RPM | 175-200 |
| 10K RPM | 125-150 |
| 7.2K RPM | 50-75 |
| RAID5 из 6 дисков с 10000 RPM | 900 |
Ниже приведены ряд рекомендаций по производительности дисков в IOPS для распространенных сервисов:
Анализ производительности ВМ в VMware vSphere. Часть 3: Storage

Сегодня разберем метрики дисковой подсистемы в vSphere. Проблема со стораджем – самая частая причина медленной работы виртуальной машины. Если в случаях с CPU и RAM траблшутинг заканчивается на уровне гипервизора, то при проблемах с диском, возможно, придется разбираться с сетью передачи данных и СХД.
Тему буду разбирать на примере блочного доступа к СХД, хотя при файловом доступе счетчики примерно те же.
Немного теории
Когда говорят о производительности дисковой подсистемы виртуальных машин, обычно обращают внимание на три связанных друг с другом параметра:
Пропускная способность важна для нагрузок последовательного характера: доступ к блокам, расположенным друг за другом. Например, такую нагрузку могут генерировать файловые сервера (но не всегда) и системы видеонаблюдения.
Пропускная способность связана с количеством операций ввода/вывода следующим образом:
Throughput = IOPS * Block size, где Block size – это размер блока.
Размер блока является довольно важной характеристикой. Современные версии ESXi пропускают блоки размером до 32 767 КБ. Если блок еще больше, он делится на несколько. Не все СХД могут эффективно работать с такими большими блоками, поэтому в Advanced Settings ESXi есть параметр DiskMaxIOSize. С помощью него можно уменьшить максимальный размер блока, пропускаемого гипервизором (подробнее здесь). Рекомендую перед изменением данного параметра проконсультироваться с производителем СХД или хотя бы протестировать изменения на лабораторном стенде.
Большой размер блока может пагубно сказываться на производительности СХД. Даже если количество IOPS и throughput относительно невелики, при большом размере блока могут наблюдаться высокие задержки. Поэтому обращайте внимание на этот параметр.
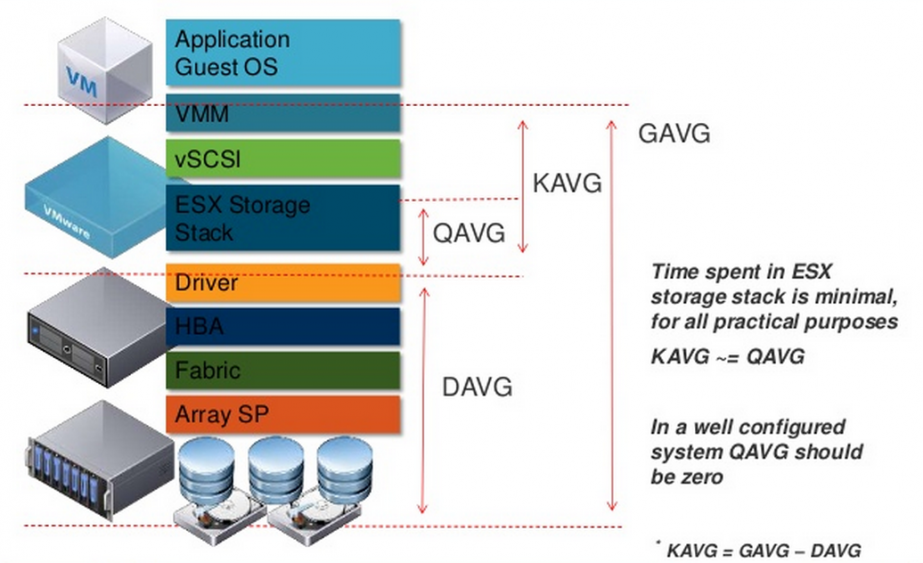
Latency – самый интересный параметр производительности. Задержка операций ввода/вывода для виртуальной машины складывается из:
GAVG и DAVG измеряются, а KAVG рассчитывается: GAVG–DAVG.
Источник
Остановимся подробнее на KAVG. При нормальной работе KAVG должен стремиться к нулю или, по крайней мере, быть сильно меньше, чем DAVG. Единственный известный мне случай, когда KAVG ожидаемо высокий, – ограничение по IOPS на диске ВМ. В таком случае при попытке превышения лимита будет расти KAVG.
Самой значительной составляющей KAVG является QAVG – время в очереди на обработку внутри гипервизора. Остальные составляющие KAVG пренебрежимо малы.
Очередь в драйвере дискового адаптера и очереди к лунам имеет фиксированный размер. Для высоконагруженных сред данный размер бывает полезно увеличить. Здесь описано, как увеличить очереди в драйвере адаптера (одновременно увеличится очередь к лунам). Данная настройка работает, когда с луном работает только одна ВМ, что бывает редко. Если на луне несколько ВМ, необходимо также увеличить параметр Disk.SchedNumReqOutstanding (инструкция здесь). Увеличив очередь, вы уменьшаете QAVG и KAVG соответственно.
Но, опять же, сначала ознакомьтесь с документацией от вендора HBA и протестируйте изменения на лабораторном стенде.
На размер очереди к луну может влиять включение механизма SIOC (Storage I/O Control). Он обеспечивает равномерный доступ к луну со стороны всех серверов кластера за счет динамического изменения очереди к луну на серверах. То есть, если на каком-то из хостов работает ВМ, которая требует непропорционально много производительности (noisy neighbor VM), SIOC уменьшает длину очереди к луну на данном хосте (DQLEN). Подробнее здесь.
С KAVG разобрались, теперь немного о DAVG. Тут все просто: DAVG – это задержка, которую вносит внешняя среда (сеть передачи данных и СХД). В любой современной и не очень СХД есть свои счетчики производительности. Для анализа проблем с DAVG имеет смысл смотреть на них. Если же со стороны ESXi и СХД все нормально, проверяйте сеть передачи данных.
Чтобы не было проблем с производительностью, выбирайте правильную Path Selection Policy (PSP) для вашей СХД. Практически все современные СХД поддерживают PSP Round-Robin (с ALUA, Asymmetric Logical Unit Access, или без). Данная политика позволяет использовать все доступные пути к СХД. В случае с ALUA используются только пути до контроллера, который владеет луном. Не для всех СХД на ESXi есть дефолтные правила, которые устанавливают политику Round-Robin. Если для вашего СХД правила нет, используйте плагин от производителя СХД, который создаст соответствующее правило на всех хостах кластера, или создайте правило самостоятельно. Подробности здесь.
Также часть производителей СХД рекомендуют менять количество IOPS на путь со стандартного значения 1000 на 1. В нашей практике это позволяло «выжать» из СХД больше производительности и значительно сократить время, которое требуется на failover в случае выхода из строя или обновления контроллеров. Сверьтесь с рекомендациями вендора, и если противопоказаний нет, то попробуйте изменить данный параметр. Подробности здесь.
Основные счетчики производительности дисковой подсистемы виртуальной машины
Счетчики производительности дисковой подсистемы в vCenter собраны в разделах Datastore, Disk, Virtual Disk:
В разделе Datastore находятся метрики по дисковым хранилищам vSphere (датасторам), на которых лежат диски ВМ. Здесь вы найдете стандартные счетчики по:
В разделе Disk находятся метрики по блочным устройствам, которые используются ВМ. Тут есть счетчики по IOPS типа summation (количество операций ввода/вывода за период измерения) и несколько счетчиков, относящихся к блочному доступу (Commands aborted, Bus resets). Данную информацию, на мой взгляд, также удобнее смотреть в ESXTOP.
Раздел Virtual Disk – самый полезный с точки зрения поиска проблем производительности дисковой подсистемы ВМ. Здесь можно посмотреть производительность по каждому виртуальному диску. Именно эта информация нужна, чтобы понять, есть ли проблема у конкретной виртуальной машины. Помимо стандартных счетчиков количества операций ввода/вывода, объема чтения/записи и задержек, в данном разделе присутствуют полезные счетчики, которые показывают размер блока: Read/Write request size.
На картинке ниже график производительности диска ВМ, на котором можно увидеть количество IOPS, задержки и размер блока.
Также метрики производительности можно посмотреть по всему датастору, если включен SIOC. Здесь представлена базовая информация по средней Latency и IOPS’ам. По умолчанию данную информацию можно посмотреть только в реальном времени.
ESXTOP
В ESXTOP несколько экранов, на которых представлена информация по дисковой подсистеме хоста в целом, отдельным виртуальным машинам и их дискам.
Начнем с информации по виртуальным машинам. Экран “Disk VM” вызывается клавишей “v”:
NVDISK – это количество дисков ВМ. Чтобы посмотреть информацию по каждому диску, нажмите “e” и введите GID интересующей ВМ.
Значение остальных параметров на данном экране понятно из их названий.
Еще один полезный при поиске проблем экран – Disk adapter. Вызывается клавишей “d” (на картинке ниже выбраны поля A,B,C,D,E,G):
NPTH – количество путей к лунам, которые видны с данного адаптера. Чтобы получить информацию по каждому пути на адаптере, нажмите “e” и введите название адаптера:
AQLEN – максимальный размер очереди на адаптере.
Также на этом экране представлены счетчики задержек, о которых я рассказывал выше: KAVG/cmd, GAVG/cmd, DAVG/cmd, QAVG/cmd.
На экране Disk device, который вызывается клавишей “u”, представлена информация по отдельным блочным устройствам – лунам (на картинке ниже выбраны поля A, B, F, G, I). Здесь можно увидеть состояние очереди к лунам.
DQLEN – размер очереди для блочного устройства.
ACTV – количество команд ввода/вывода в ядре ESXi.
QUED – количество команд ввода/вывода в очереди.
%USD – ACTV / DQLEN × 100%.
LOAD – (ACTV + QUED) / DQLEN.
Если %USD высокий, стоит рассмотреть возможность увеличения очереди. Чем больше команд в очереди, тем выше QAVG и, соответственно, KAVG.
Также на экране Disk device можно посмотреть, работает ли на СХД VAAI (vStorage API for Array Integration). Для этого нужно выбрать поля A и O.
Механизм VAAI позволяет перенести часть работы из гипервизора непосредственно на СХД, например, зануление, копирование блоков или блокировки.
Как видно на картинке выше, на данной СХД VAAI работает: активно используются примитивы Zero и ATS.
Анализ производительности ВМ в VMware vSphere. Часть 3: Storage
Рассказываем, какие метрики помогут отследить проблемы с производительностью дисковой подсистемы VMware vSphere.

Сегодня разберем метрики дисковой подсистемы в vSphere. Проблема со стораджем – самая частая причина медленной работы виртуальной машины. Если в случаях с CPU и RAM траблшутинг заканчивается на уровне гипервизора, то при проблемах с диском, возможно, придется разбираться с сетью передачи данных и СХД.
Предмет буду разбирать на примере блочного доступа к СХД, хотя при файловом доступе счетчики примерно те же.
Немного теории
Когда говорят о производительности дисковой подсистемы виртуальных машин, обычно обращают внимание на три связанных друг с другом параметра:
Количество IOPS обычно важно для нагрузок произвольного характера (random): доступ к блокам на диске, расположенным в разных местах. Примером такой нагрузки могут послужить базы данных, бизнес-приложения (ERP, CRM) и т.д.
Пропускная способность важна для нагрузок последовательного характера: доступ к блокам, расположенным друг за другом. Например, такую нагрузку могут генерировать файловые сервера (но не всегда) и системы видеонаблюдения.
Пропускная способность связана с количеством операций ввода/вывода следующим образом:
Throughput = IOPS * Block size, где Block size – это размер блока.
Размер блока является довольно важной характеристикой. Современные версии ESXi пропускают блоки размером до 32 767 КБ. Если блок еще больше, он делится на несколько. Не все СХД могут эффективно работать с такими большими блоками, поэтому в Advanced Settings ESXi есть параметр DiskMaxIOSize. С помощью него можно уменьшить максимальный размер блока, пропускаемого гипервизором (подробнее здесь). Рекомендую перед изменением данного параметра проконсультироваться с производителем СХД или хотя бы протестировать изменения на лабораторном стенде.
Большой размер блока может пагубно сказываться на производительности СХД. Даже если количество IOPS и throughput относительно невелики, при большом размере блока могут наблюдаться высокие задержки. Поэтому обращайте внимание на этот параметр.
Latency – самый интересный параметр производительности. Задержка операций ввода/вывода для виртуальной машины складывается из:
Общая задержка, которая видна в гостевой ОС (GAVG, Average Guest MilliSec/Command), – это сумма KAVG и DAVG.
GAVG и DAVG измеряются, а KAVG рассчитывается: GAVG–DAVG.
Источник
Остановимся подробнее на KAVG. При нормальной работе KAVG должен стремиться к нулю или, по крайней мере, быть сильно меньше, чем DAVG. Единственный известный мне случай, когда KAVG ожидаемо высокий, – ограничение по IOPS на диске ВМ. В таком случае при попытке превышения лимита будет расти KAVG.
Самой значительной составляющей KAVG является QAVG – время в очереди на обработку внутри гипервизора. Остальные составляющие KAVG пренебрежимо малы.
Размер очереди в драйвере дискового адаптера и очереди к лунам имеет фиксированный размер. Для высоконагруженных сред данный размер бывает полезно увеличить. Здесь описано, как увеличить очереди в драйвере адаптера (помните, что одновременно увеличится очередь к лунам). Данная настройка работает, когда с луном работает только одна ВМ, что бывает редко. Если на луне несколько ВМ, необходимо также увеличить параметр Disk.SchedNumReqOutstanding (инструкция здесь). Увеличив очередь, вы уменьшаете QAVG и KAVG соответственно.
Но, опять же, сначала ознакомьтесь с документацией от вендора HBA и протестируйте изменения на лабораторном стенде.
На размер очереди к луну может влиять включение механизма SIOC (Storage I/O Control). Он обеспечивает равномерный доступ к луну со стороны всех серверов кластера за счет динамического изменения очереди к луну на серверах. То есть, если на каком-то из хостов работает ВМ, которая требует непропорционально много производительности (noisy neighbor VM), SIOC уменьшает длину очереди к луну на данном хосте (DQLEN). Подробнее здесь.
С KAVG разобрались, теперь немного о DAVG. Тут все просто: DAVG – это задержка, которую вносит внешняя среда (сеть передачи данных и СХД). В любой современной и не очень СХД есть свои счетчики производительности. Для анализа проблем с DAVG имеет смысл смотреть на них. Если же со стороны ESXi и СХД все нормально, проверяйте сеть передачи данных.
Чтобы не было проблем с производительностью, выбирайте правильную Path Selection Policy (PSP) для вашей СХД. Практически все современные СХД поддерживают PSP Round-Robin (с ALUA, Asymmetric Logical Unit Access, или без). Данная политика позволяет использовать все доступные пути к СХД. В случае с ALUA используются только пути до контроллера, который владеет луном. Не для всех СХД на ESXi есть дефолтные правила, которые устанавливают политику Round-Robin. Если для вашего СХД правила нет, используйте плагин от производителя СХД, который создаст соответствующее правило на всех хостах кластера, или создайте правило самостоятельно. Подробности здесь.
Также часть производителей СХД рекомендуют менять количество IOPS на путь со стандартного значения 1000 на 1. В нашей практике это позволяло «выжать» из СХД больше производительности и значительно сократить время, которое требуется на failover в случае выхода из строя или обновления контроллеров. Сверьтесь с рекомендациями вендора, и если противопоказаний нет, то попробуйте изменить данный параметр. Подробности здесь.
Основные счетчики производительности дисковой подсистемы виртуальной машины
Счетчики производительности дисковой подсистемы в vCenter собраны в разделах Datastore, Disk, Virtual Disk:

В разделе Datastore находятся метрики по дисковым хранилищам vSphere (датасторам), на которых лежат диски ВМ. Здесь вы найдете стандартные счетчики по:
Из названий счетчиков в принципе все понятно. Еще раз обращу внимание, что здесь статистика не по конкретной ВМ (или диску ВМ), а общая по всему датастору. На мой взгляд, данную статистику удобнее смотреть в ESXTOP, хотя бы исходя из того, что минимальный период измерения там 2 секунды.
В разделе Disk находятся метрики по блочным устройствам, которые используются ВМ. Тут есть счетчики по IOPS типа summation (количество операций ввода/вывода за период измерения) и несколько счетчиков, относящихся к блочному доступу (Commands aborted, Bus resets). Данную информацию, на мой взгляд, также удобнее смотреть в ESXTOP.
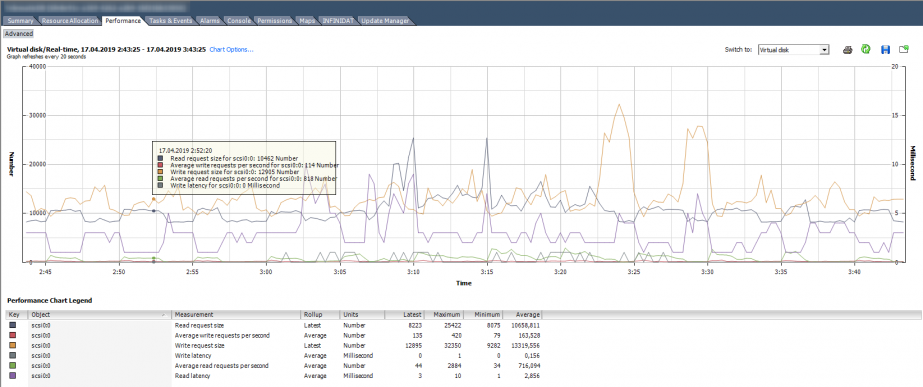
Раздел Virtual Disk – самый полезный с точки зрения поиска проблем производительности дисковой подсистемы ВМ. Здесь можно посмотреть производительность по каждому виртуальному диску. Именно эта информация нужна, чтобы понять, есть ли проблема у конкретной виртуальной машины. Помимо стандартных счетчиков количества операций ввода/вывода, объема чтения/записи и задержек, в данном разделе присутствуют полезные счетчики, которые показывают размер блока: Read/Write request size.
На картинки ниже график производительности диска ВМ, на котором можно увидеть количество IOPS, задержки и размер блока.
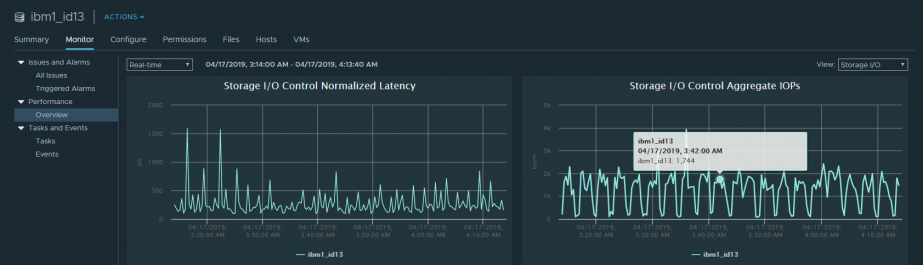
Также метрики производительности можно посмотреть по всему датастору, если включен SIOC. Здесь представлена базовая информация по средней Latency и IOPS’ам. По умолчанию данную информацию можно посмотреть только в реальном времени.
ESXTOP
В ESXTOP несколько экранов, на которых представлена информация по дисковой подсистеме хоста в целом, отдельным виртуальным машинам и их дискам.
Начнем с информации по виртуальным машинам. Экран “Disk VM” вызывается клавишей “v”:

NVDISK – это количество дисков ВМ. Чтобы посмотреть информацию по каждому диску, нажмите “e” и введите GID интересующей ВМ.
Значение остальных параметров на данном экране понятно из их названий.
Еще один полезный при поиске проблем экран – Disk adapter. Вызывается клавишей “d” (на картинке ниже выбраны поля A,B,C,D,E,G):

NPTH – количество путей к лунам, которые видны с данного адаптера. Чтобы получить информацию по каждому пути на адаптере, нажмите “e” и введите название адаптера:
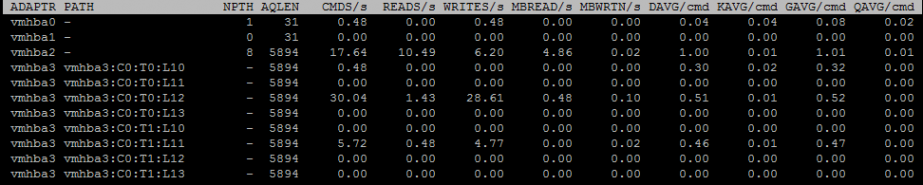
AQLEN – максимальный размер очереди на адаптере.
Также на этом экране представлены счетчики задержек, о которых я рассказывал выше: KAVG/cmd, GAVG/cmd, DAVG/cmd, QAVG/cmd.
На экране Disk device, который вызывается клавишей “u”, представлена информация по отдельным блочным устройствам – лунам (на картинке ниже выбраны поля A, B, F, G, I). Здесь можно увидеть состояние очереди к лунам.

DQLEN – размер очереди для блочного устройства.
ACTV – количество команд ввода/вывода в ядре ESXi.
QUED – количество команд ввода/вывода в очереди.
%USD – ACTV / DQLEN × 100%.
LOAD – (ACTV + QUED) / DQLEN.
Если %USD высокий, стоит рассмотреть возможность увеличения очереди. Чем больше команд в очереди, тем выше QAVG и, соответственно, KAVG.
Также на экране Disk device можно посмотреть, работает ли на СХД VAAI (vStorage API for Array Integration). Для этого нужно выбрать поля A и O.
Механизм VAAI позволяет перенести часть работы из гипервизора непосредственно на СХД, например, зануление, копирование блоков или блокировки.

Как видно на картинке выше, на данной СХД VAAI работает: активно используются примитивы Zero и ATS.



