Распознавание номеров: от А до 9. Часть 3
Неделю назад мы опубликовали статью про открытый сервер для распознавания изображений автомобильных номеров. Теперь, как и обещали, статья про то, как отправлять на него свои фотографии с номерами. Наша цель была, как вы помните, вовсе не ругаться друг на друга неприличными словами, а именно сделать функционирующий сервер в интернете, который справляется с фотографиями и отправляет назад результат распознавания.

(часть фотографий, присланных в течение недели)
Хочется рассказать еще и о том, как мы — программисты, ворочающие нос от интернет технологий и Linux, — решали проблему с сервером.
Все мысли по поводу настоящего шумного компьютера под ухом, протягивание кабеля на кухню и переговоров с провайдером про реальный IP, были отброшены, как не соответствующие новым реалиям (со всех сторон только и говорят про облачные сервисы и прочие новинки). Но еще хотелось удобства, привычного Windows, dotNET, да и вообще возможности по-живому отлаживаться на сервере. Посему было решено: виртуальный сервер с Windows Server и удаленный рабочий стол.
Хочу передать огромное спасибо терпеливым и вежливым парням в техподдержке! Так что справились.
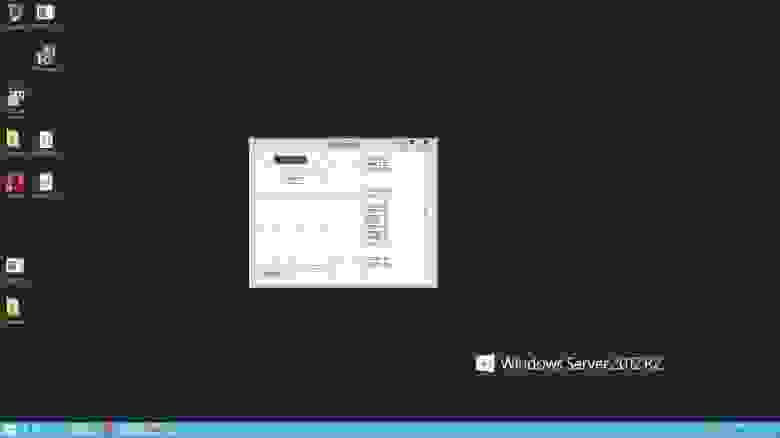
Да-да, вот так все просто выглядит. Это принтскрин с удаленного доступа к виртуальному серверу (да не сочтите это рекламой Windows Server 2012 R2).
Затем надо было написать http ответчик. Хотелось как можно проще и не связываться с IIS, нужно было уложиться в пару дней на разработку. Но оказалось очень просто скачать пример SimpleHttpServer и в функцию:
«, data); >
вписывать нужную обработку. Надеюсь, мы не нарушили никакой лицензии.
А тем специалистам Web безопасности, у которых сейчас на спине зашевелились волосы от такой реализации… огромный привет и приглашение сделать нам все по умному!
Доступ к серверу
Сервер распознавания работает, как очень простой http сайт. Пользователь отправляет на страницу post-сообщение в формате http, в котором содержится лишь один параметр — изображение. В ответ получает результат распознавания.
Для запроса из БД, если в этом есть необходимость, нужно отправить 2 строки: автомобильный номер в текстовом виде и уникальный ID.
В Android программе было 3 запроса, их код выглядит следующим образом:
1) отправка предварительно выделенного номера серверу:
2) отправка запроса по номеру:
По-моему, комментировать тут особенно нечего. HttpPost файла и HttpPost двух текстовых строк.
Не забывайте, что в условиях использования мобильного интернета, приходится отправлять область с предварительно обнаруженным номером с помощью каскадного детектора Хаара.
Пример кода выделения Хааром с помощью OpenCV на Android Java:
Здесь заметьте важную мелочь: после детектирования прямоугольника номера его границы несколько расширяются, т. к. детектор с некоторой вероятностью может ошибаться с масштабом.
И по просьбе трудящихся добавили http заход на функцию поиска и распознавания номера в целом кадре: 212.116.121.70:10000/uploadimage
В ответ получите список найденных номеров и некий критерий качества распознавания по каждому (больше — лучше):
x000xx99 90%
a111aa197 75%
строки разделены «\r\n»
Найдено 2 номера, первый более качественный (90%), второй менее (75%).
Теперь можно не выделять хааром изображение, а сразу все изображение отправлять целиком. Так проще организовать автоматическое тестирование алгоритмов.
На других платформах код должен получаться не намного сложнее.
Несколько слов о трех днях полета сервера распознавания номеров
Программу на Android для ругани на автомобили Recognitor мы выложили 13 мая. У меня чувства смешанные: от гордости от того, что оно работает, до сжигающего стыда за случающиеся ошибки в алгоритме распознавания, когда прямо на глазах приходит чистый четкий номер, но пользователю возвращается абракадабра.
Количество отправленных на сервер изображений: 1700
Из них оказалось номерами РФ: 1370
Количество распознанных: 830
(с точностью до 10ти указано)
Вот тут стоит отдельно пояснить «из них оказалось номерами РФ». Мы не учли, что хабр хорошо читают на территории СНГ и нигде не указали, что номера должны быть РФ. Естественно, сюда же относятся и ошибки не идеально обученного каскадного детектора, который часто ошибался в непривычной ситуации съемки с монитора. И было несколько десятков зеркально отраженных номеров, т. е. пользователь не выбрал в меню “Flip”. Также ну очень сильно размазанные (не читаемые глазами) я тоже отнес сюда.
В промежуточном итоге результат не фантастический, мы сделали выводы, уже выпустили 2 обновления Android программы, поправив косяки и дав пользователю новую волшебную функцию выделения области номера пальцем. Изменили алгоритмы на сервере. О том, что интересного мы поменяли в самих алгоритмах, в моей следующей статье (воспользовались парой альтернативных методов из предыдущей моей статьи).
Но, не смотря на не идеальную работу, пользователям приложение пришлось по душе! Оценки в GooglePlay радовали.
И да, конечно, поощрим бесспорных победителей:
P494KE_197 — обозван 226 раз (конечно, это ZlodeiBaal)
X777XX_77 – обозван 21 раз (в топе запроса яндекса на запрос «номера»)
Даже поймали A362MP_97, А231МР_97 и А869МР_97 (возможно, тоже из интернета).
Удачи
Вообще, алгоритм обучался на очень грязных зимних номерах (и парадоксально не всегда устойчиво работает на чистых), поэтому тут то его преимущества и стоит поискать. И да, действительно, часто размытые и весьма грязные номера удавалось распознать: 


Update:
1) Оказывается, обученный каскад нами на российские автомобильные номера был замержин в основную версию OpenCV
2) при предварительном выделении номера ожидали картинки довольно больших размеров в uploadimage, сейчас поправил, все приводится к одному масштабу. Должно заработать и на мелких картинках из интернета.
Разработка библиотеки распознавания российских автомобильных номеров
В настоящее время в различных областях человеческой деятельности все шире применяются технологии компьютерного зрения. Например, распознавание изображений используется в автоматизированных системах контроля производственных процессов, при проверке электронных документов, в информационных и управляющих системах различного назначения. В данной работе рассматривается распознавание автомобильных номеров, которое актуально для автоматизации работы государственных органов безопасности дорожного движения, полиции, охранных организаций. Распознавание выполняется с помощью библиотеки OpenCV
Объект исследования: методы распознавания изображений.
Предмет исследования: процесс обнаружения и распознавания автомобильного номера на цифровых изображениях с использованием метода Виолы-Джонса
Цель: разработка библиотеки, реализующей автоматическое распознавание российских автомобильных номеров.
Задачи:
1. Поиск области автомобильного номера
1.1 Метод Виолы-Джонса
В настоящее время метод Виолы–Джонса является популярным методом для поиска объекта на изображении в силу своей высокой скорости и эффективности. В основу метода Виолы–Джонса положены: интегральное представление изображения по признакам Хаара, построение классификатора на основе алгоритма адаптивного бустинга и способ комбинирования классификаторов в каскадную структуру. Эти идеи позволяют осуществлять поиск объекта в режиме реального времени. Рассмотрим их более подробно.
Интегральное представление изображения – это матрица, одинаковая по размерам с исходным изображением. В каждом элементе матрицы хранится сумма интенсивностей всех пикселов, находящихся левее и выше данного элемента – правого нижнего угла прямоугольной области (0,0) до (x,y). Элементы матрицы L можно рассчитать по формуле:
Расчёт значений элементов матрицы проходит за время, пропорциональное числу пикселов в исходном изображении, поэтому интегральное изображение просчитывается за один проход.
Элементы матрицы рассчитываются по формуле:
С помощью интегрального представления изображения можно быстро рассчитать суммарную яркость произвольной прямоугольной области на изображении. Пример вычисления приведен в приложении «А».
На этапе обнаружения объекта в методе Виолы-Джонса используется окно определенного размера, которое движется по изображению. Для каждой области изображения, над которой проходит окно, рассчитывается признак Хаара, с помощью которого происходит поиск нужного объекта.
Признак-отображение, где Df —множество допустимых значений признака. Если заданы признаки f1,…, fn, то вектор признаков x=(f1(x),…,fn(x)) называется признаковым описанием объекта x. Признаковые описания допустимо сопоставлять с самими объектами. При этом множество X=Df1*…*Dfn называют признаковым пространством.
Признаки делятся на следующие типы в зависимости от множества Df:
Признак Хаара вычисляется по смежным прямоугольным областям. В стандартном методе Виолы–Джонса используются прямоугольные примитивы, изображенные на рисунке 1.
Вычисляемым значением F признака Хаара будет где X – сумма значений яркостей точек, закрываемых светлой частью примитива, Y –сумма значений яркостей точек, закрываемых темной частью. Для вычисления используется понятие интегрального изображения, рассмотренное выше, и признаки Хаара могут вычисляться быстро, за постоянное время. Использование признаков Хаара дает точечное значение перепада яркости по оси X и Y соответственно.
Поскольку признаки Хаара мало подходят для обучения или классификации, для описания объекта с достаточной точностью необходимо большее число признаков. Поэтому признаки Хаара поступают в каскадный классификатор, служащий для быстрого отбрасывания окон, где не найден требуемый объект, и выдачи результата «истина» или «ложь» относительно нахождения объекта.
Классификатор строится на основе алгоритма бустинга (от англ. boost–улучшение, усиление) для выбора наиболее подходящих признаков для искомого объекта на данной части изображения. В общем случае бустинг — это комплекс методов, способствующих повышению точности аналитических моделей. Эффективная модель, допускающая мало ошибок классификации, называется «сильной». «Слабая» же, напротив, не позволяет надежно разделять классы или давать точные предсказания, делает большое количество ошибок. Поэтому бустинг означает «усиление» «слабых» моделей и является процедурой последовательного построения композиции алгоритмов машинного обучения, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов.
В результате работы алгоритма бустинга на каждой итерации формируется простой классификатор вида:
– направление знака неравенства, — значение порога,– вычисленное значение признака,– окно изображения размером 24×24 пикселов.
Полученный классификатор имеет минимальную ошибку по отношению к текущим значениям весов, задействованным в процедуре обучения для определения ошибки.
Поиск автомобильного номера на цифровом изображении
Для поиска объекта на цифровом изображении используется обученный классификатор, представленный в формате xml. Классификатор формируется на примитивах Хаара.
 Рисунок 2 – Структура классификатора
Рисунок 2 – Структура классификатора
где maxWeakCount – количество слабых классификаторов;
stageThereshold – максимальный порог яркости;
weakClassifiers – набор слабых классификаторов, на основе которых выносится решение о том, находится объект на изображении или нет;
internalNodes и leafValues – параметры конкретного слабого классификатора.
Первые два значения в internalNodes не используются, третье — номер признака в общей таблице признаков (она располагается в XML-файле под тегом features), четвертое — пороговое значение слабого классификатора. Если значение признака Хаара меньше порога слабого классификатора, выбирается первое значение leafValues, если больше — второе.
На рисунке 3 продемонстрированы результаты работы классификаторов первого каскада. Белые пятна обозначают предполагаемый участок для дальнейшего поиска.
На основе этого базиса строится каскад классификаторов, принимающих решение о том, распознан объект на изображении или нет. Наличие или отсутствие предмета в окне определяется разницей между значением признака и порогом, полученным в результате обучения.
На рисунке 3.1 продемонстрированы результаты поиска с использованием классификатора.
 Рисунок 3 – Результат работы классификаторов первого каскада
Рисунок 3 – Результат работы классификаторов первого каскада  Рисунок 3 – Результат работы классификаторов первого каскада
Рисунок 3 – Результат работы классификаторов первого каскада  Рисунок 3 – Результат работы классификаторов первого каскада
Рисунок 3 – Результат работы классификаторов первого каскада  Рисунок 3 – Результат работы классификаторов первого каскада
Рисунок 3 – Результат работы классификаторов первого каскада  Рисунок 3.1 – Результат работы поиска автомобильного номера
Рисунок 3.1 – Результат работы поиска автомобильного номера
Ознакомиться с процессом обучения каскада Хаара можно по ссылки на статью в моём личном блоге: https://kostyakulakov.ru/2015/07/04/opencv-обучение-каскада-хаара/ или в приложении «Б».
2. Подготовка к распознаванию автомобильного номера
2.1 Алгоритм нормализации угла наклона
После того как мы нашли автомобильный номер (Рисунок 3), нам нужно подготовить его к распознаванию, для этого мы должны нормализировать угол наклона автомобильного номера.
 Рисунок 5 – результат работы алгоритма. Угол 1.4°
Рисунок 5 – результат работы алгоритма. Угол 1.4°
2.2 Алгоритм поиска нижней границы автомобильного номера
После того как мы нашли угол наклона автомобильного номера, нам нужно найти его границы. Поиск нижней границы автомобильного номера строится на анализе гистограммы яркости.
 Рисунок 6 – принцип построения гистограммы
Рисунок 6 – принцип построения гистограммы
Для начала изображение обрабатывается с помощью определенного правила, которое задаёт условие разделение пикселей на чёрные и белые. Данная операция называется бинаризация изображения. После бинаризации мы считаем в каждой колонке кол-во чёрных пикселей и на основе полученной информации строим гистограмму изображения. Принцип построения гистограммы отображён на рисунке 6. Пример бинаризированного автомобильного номера и его гистограммы приведён на рисунке 7.
 Рисунок 7 – бинаризация автомобильного номера и гистограмма
Рисунок 7 – бинаризация автомобильного номера и гистограмма
Из рисунка видно, что имеются резкие возрастания уровня гистограммы в начале и конце автомобильного номера. В алгоритме анализируются данные возрастания.
На их основе строится гипотеза о нижней границе автомобильного номера.
Полная блок-схема алгоритма поиска нижней границы приведена в приложении «Г».
2.3 Алгоритм поиска верхней границы автомобильного номера
Во время тестов опытным путём установлено, что гипотеза с использованием гистограммы яркости для поиска верхней границы, а/н [1] работает в 50% случаев, что не приемлемо для нашей системы. В связи с этим было решено обучить каскад Хаара на каждую букву и проанализировать верхние границы букв, тем самым мы сможем получить верхнюю границу автомобильного номера. Подробнее про процесс обучения каскада Хаара для поиска букв автомобильного номера можно ознакомиться в моём личном блоге: https://kostyakulakov.ru/2015/07/04/opencv-обучение-каскада-хаара или в приложении «Б». Пример работы алгоритма приведён на рисунке 8. Полная блок-схема алгоритма поиска верхней границы приведена в приложении «Д».
В некоторых случаях, алгоритм с использованием каскада Хаара может не дать результата, это характерно для изображений с очень низким разрешением. Для таких изображений мы применяем как альтернативный алгоритм поиск границы с использованием гистограммы яркости.
2.4 Алгоритм поиска боковых границ автомобильного номера
На данном этапе мы уже обрезали автомобильный номер по верхней и нижней границе, остаётся определить боковые границы автомобильного номера. В данном случае, мы будем применять метод построения гистограммы яркости, но у нас появляется проблема: цвет автомобиля. Если автомобиль белого цвета, то после бинаризации изображение по краям будет иметь белый цвет, а если автомобиль чёрного цвета, то края будут чёрные, а сам номер белым. Отсюда следует вывод, что нам следует использовать две гипотезы на каждый бок, одна для поиска границы на белой машине и вторая для поиска на чёрной границе. Выигрывает та гипотеза результатом исследования, которой является результат ближайший к центру автомобильного номера. Для улучшения качества поиска боковых границ автомобильного номера, перед построением гистограммы яркости мы проводим основные морфологические преобразования:
Пример бинаризации кадра белой и чёрной машины приведён на рисунке 9. Полная блок-схема алгоритма поиска боковых границ приведена в приложении «Е».
3. Сегментации автомобильного номера на символы
Результатом работы алгоритма поиска боковых границ автомобильного номера, является изображение номера, для которого применим алгоритма сегментации на символы. Пример полученного автомобильного номера после выполнения алгоритма поиска боковых границ приведён на рисунке 10.
Для поиска символов автомобильного номера мы используем стандартные методы библиотеки OpenCV. Вначале нам необходимо перевести изображение в чёрно-белый формат и бинаризировать его. После бинаризации мы обрабатываем изображения фильтром средних частот, чтобы убрать помеховую составляющую. Следующим действием будет процесс размытие изображения с использованием метода Гаусса. Размытие необходимо для сглаживания краёв символов как показали тесты, данное преобразование существенно увеличивает вероятность успешного поиска символа. В следующем шаге мы воспользуемся самым популярным методом для выделения границ – детектором границ Кенни. Алгоритм детектора достаточно тривиален и заключается в следующем:
Результаты и шаги преобразования автомобильного номера отображены на рисунке 11. После выделения границ мы используем стандартную функцию для поиска связанных областей. Окончательным этапом поиска связанных областей является сравнения найденной области с шаблоном символа автомобильного номера и отбрасыванием некорректных областей. Результат выделения символов приведён на рисунке 12. К тому же, данный способ позволяет корректно определять символы автомобильного номера на изображении с повышенной помеховой составляющей, пример приведён на рисунке 13. Блок схема алгоритма приведена в приложении «Ё».
4. Распознавание символов автомобильного номера
 Распознавание символов является заключительным этапом работы библиотеки, на текущий момент мы имеем массив с выделенными символами автомобильного номера. Для распознавания символов было принято решение использовать готовый, проверенный временем, продукт от компании Google – Tesseract OCR. Библиотека для распознавания символов Tesseract OCR использует нейронную сеть, которую нам пришлось обучить с учётом шаблона символа автомобильного номера. Во время сборки Tesseract OCR под компилятор mingw32 мы столкнулись с определенными проблемами. Мы просмотрели множество it ресурсов и не обнаружили подробной инструкции для сборки под mingw, поэтому мы решили написать статью и опубликовали её на habrahabr, ссылка на статью и сама статья расположена в приложении «Ж». Блок-схема алгоритма распознавания символов автомобильного номера приведена в приложении «З».
Распознавание символов является заключительным этапом работы библиотеки, на текущий момент мы имеем массив с выделенными символами автомобильного номера. Для распознавания символов было принято решение использовать готовый, проверенный временем, продукт от компании Google – Tesseract OCR. Библиотека для распознавания символов Tesseract OCR использует нейронную сеть, которую нам пришлось обучить с учётом шаблона символа автомобильного номера. Во время сборки Tesseract OCR под компилятор mingw32 мы столкнулись с определенными проблемами. Мы просмотрели множество it ресурсов и не обнаружили подробной инструкции для сборки под mingw, поэтому мы решили написать статью и опубликовали её на habrahabr, ссылка на статью и сама статья расположена в приложении «Ж». Блок-схема алгоритма распознавания символов автомобильного номера приведена в приложении «З».
5. Основные методы библиотеки
В данном пункте описаны основные методы библиотеки распознавания автомобильных номеров.
| Имя метода | Входные данные | Выходные данные | Описание |
| recognize | Изображение | Текст | Распознавание изображения |
| getLicenseText | — | Текст | Возвращение распознанного автомобильного номера |
| getFrames | — | Изображение | Возвращение найденной области с автомобильным номером |
| findLetters | Изображение | Координаты | Выделение связанных областей и нормализация изображения |
| setImage | Изображение | — | Установка изображения для распознавания |
| showSymbol | — | — | демонстрация на экран изображений с найденными символами на автомобильном номере |
| saveSymbols | — | — | Сохраняет на диск пользователя найденные символы на области автомобильного номера |
| saveFrame | — | — | Сохраняет на диск пользователя найденные области на автомобильном номере |
| recognizeLetters | Координаты | Текст | Распознание найденных символов |
| showNormalImage | — | — | Демонстрация изображения для распознавания |
6. Практическое применение разработанной библиотеки: тестовый запуск программы на охраняемом объекте
В рамках проекта была разработана открытая библиотека распознавания автомобильных номеров. Программа, написанная с использованием функций библиотеки, была апробирована в частном охранном предприятии. Для проверки был записан на видео въезд машины на территорию; программа осуществила выделение автомобильного номера, текстовое представление которого может быть подвергнуто дальнейшей обработке. Для демонстрации представляю несколько кадров из видеозаписи. На рисунке 10 приведено изображение и результат работы программы по идентификации номера.
Результаты работы программы по распознаванию номера приведены на рисунке 11.
 Рисунок 11 – Демонстрация работы программы на примере входных данных в виде видео
Рисунок 11 – Демонстрация работы программы на примере входных данных в виде видео
Заключение
Дальнейшее развитие проекта включает улучшение работы алгоритма отсечения помеховой составляющей изображения.
Список использованных источников
Приложение «А»
Пример расчёта интегральной матрицы
У нас есть прямоугольник ABCD с интересующим объектом D (рисунок А.1):
 Рисунок А.1
Рисунок А.1
На рисунке видно, что сумму внутри прямоугольника можно выразить через суммы и разности смежных прямоугольников по следующей формуле:
Примерный подсчёт показан на рисунке А.2:
 Рисунок А.2
Рисунок А.2



